The image above is of the Douro River in Porto. I was surprised to see so many port manufacturers clustered in the same part of the town, all on the same side of the river and within a relatively small area . Quite different from the more dispersed pattern I would normally expect from wine producers. I’m deliberately avoiding any neat metaphors about research or guideline development here. I just thought it was interesting.
I am not a clinician but a guideline methodology expert; you can read my full disclaimer here.
Where GRADE Porto suggests evidence-based guidance is heading
This post reflects my interpretation of broad themes emerging from discussions at the recent GRADE Working Group meeting in Porto. It is not intended as a summary of specific sessions or ongoing projects, but rather as a reflection on wider methodological and strategic directions within evidence-based guidance.
The recent GRADE Working Group meeting in Porto highlighted several interesting refinements across guideline methodology and persistent challenges in producing trustworthy recommendations. Across these discussions, two related but distinct themes stood out to me.
The first is a gradual shift toward more automated and scalable evidence processes combined with an increasing emphasis on human judgement. The second is a growing recognition that guideline development is not only about interpreting evidence, but also about systematically shaping future research.
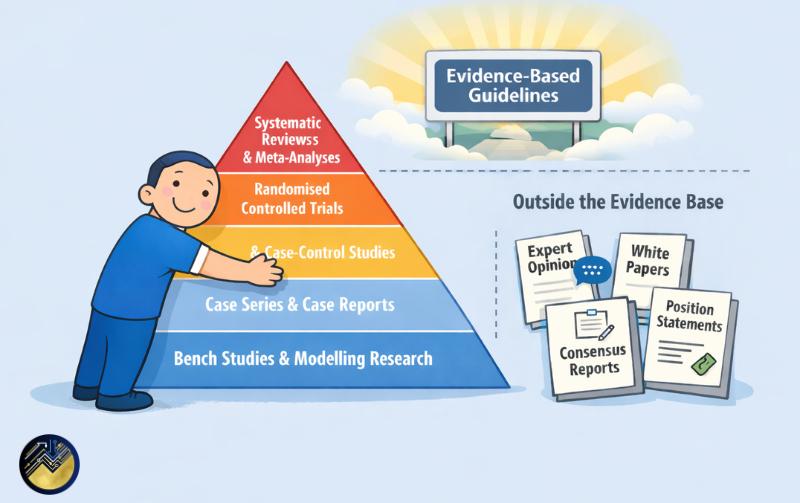
Many of the discussions suggested that evidence-based guidance is moving into a phase where methodological refinement is no longer the sole focus. Over the past decade, evidence workflows have already undergone substantial automation, well before the emergence of current AI systems. Improved database search platforms, automated de-duplication, online risk-of-bias tools, semi-automated screening, structured data extraction, PDF retrieval systems, and support for more efficient search strategies (including improved “pearl growing” approaches) have progressively reduced the manual burden of evidence synthesis. Building on this trajectory, newer AI-enabled tools are further extending what can be automated across evidence retrieval, synthesis, and surveillance.
Should we be worried? I don’t think so. None of this removes the need for human judgement. It just changes its role because judgement now becomes more central and more explicit. The emerging challenge is how to make expert interpretation more transparent, particularly in contexts involving uncertainty, indirect evidence, competing outcomes, or contextual constraints that cannot be resolved by algorithm.
In this sense, AI-enabled tools and automated platforms can be regarded as extensions of the evidence process rather than replacements for expert reasoning. They increase efficiency, but they also increase the importance of direction-setting and correction when outputs are flawed, which can only be corrected if errors are identified by an expert human operator. This is where methodological expertise becomes essential: knowing how to frame the question, how to translate it into a usable workflow, what to ask of the system, and how to recognise whether the outputs are valid. It also requires judgement about where efficiency can be safely introduced and where rigour must be maintained, as well as the ability to check that automated processes have actually done what they were intended to do. In practice, this depends on a deep understanding of guideline methodology and what might be described as a form of epistemic control: the ability to define, shape, and critically interrogate how evidence is generated and interpreted, rather than use the technology blindly.
A second, equally important theme is the growing recognition that guideline development should not be seen solely as the endpoint of evidence synthesis. As guidelines are updated, rapidly in some areas, it becomes increasingly clear that primary research does not always produce the evidence that guideline developers and clinicians need for decision-making. It is therefore unsurprising that many methodologists now see guideline methodology as a mechanism that should also be used for identifying what is not known, so that we can feed those gaps back into the research system.
I may be somewhat biased here, having previously written about the extent to which research effort can become misaligned with actual needs. In some areas, evidence continues to accumulate around questions that are already reasonably well understood, including the use of proxy outcomes that are only weakly connected to clinically meaningful endpoints, despite the existence of more direct evidence. At the same time, other clinically important uncertainties remain unresolved across many areas, despite repeated acknowledgement that evidence is lacking or highly uncertain. This becomes particularly important in areas where evidence is persistently sparse or difficult to generate.
Rare diseases are a clear example, but similar issues arise in areas such as infection prevention and control, where some interventions became embedded in practice long before rigorous evaluation was commonplace. Experimental designs in these settings are often constrained by ethical or practical realities. In addition, many funding systems have historically operated on the basis that the best application wins, meaning that research topics have often been shaped by the interests and capacity of applicants rather than by systematic assessments of clinical need. This approach has been understandable, because there were large gaps in evidence across many areas and expanding the overall research base was the priority.
A related issue is that parts of the research system can generate evidence that is methodologically valid but of limited clinical relevance, particularly where surrogate outcomes are used in place of patient-important endpoints without a clearly established causal pathway between them. Concerns about poorly designed or poorly reported trials, recognised since the early years of evidence-based medicine, remain unresolved and continue to add to this methodological challenge.
It is time that we move from research volume to more explicit design and prioritisation, a gap that guideline processes are well placed to help address. Without this, guideline updates risk repeating the same conclusions across successive editions, acknowledging uncertainty without creating a realistic pathway for resolving it.
Concluding reflections
Taken together, the discussions in Porto suggested to me that evidence-based guidance is entering a phase defined by two parallel shifts. The first is the integration of automation with increasingly explicit, structured, and defensible human judgement. The second is a movement toward viewing guideline development as part of a broader evidence ecosystem that not only evaluates research, but also actively shapes what research is needed next.
Producing trustworthy recommendations depends not only on methodological sophistication in evidence synthesis, but also on the ability to connect evidence processes to real-world decision-making and research prioritisation. In that sense, guideline systems are becoming less like static products and more like coordinating infrastructures within a continuously evolving evidence landscape. This also implies a more active role in shaping and directing evidence generation, and it was encouraging to hear similar perspectives reflected across many of the discussions. As automation reduces the burden of some traditional synthesis tasks, guideline methodologists have increasing scope to focus more deliberately on these higher-order functions.
That, to me, was one of the clearest signals emerging from Porto: that guideline systems are shifting from endpoints of evidence synthesis and recommendations toward coordinating infrastructures that both interpret evidence and actively shape what research is needed next.